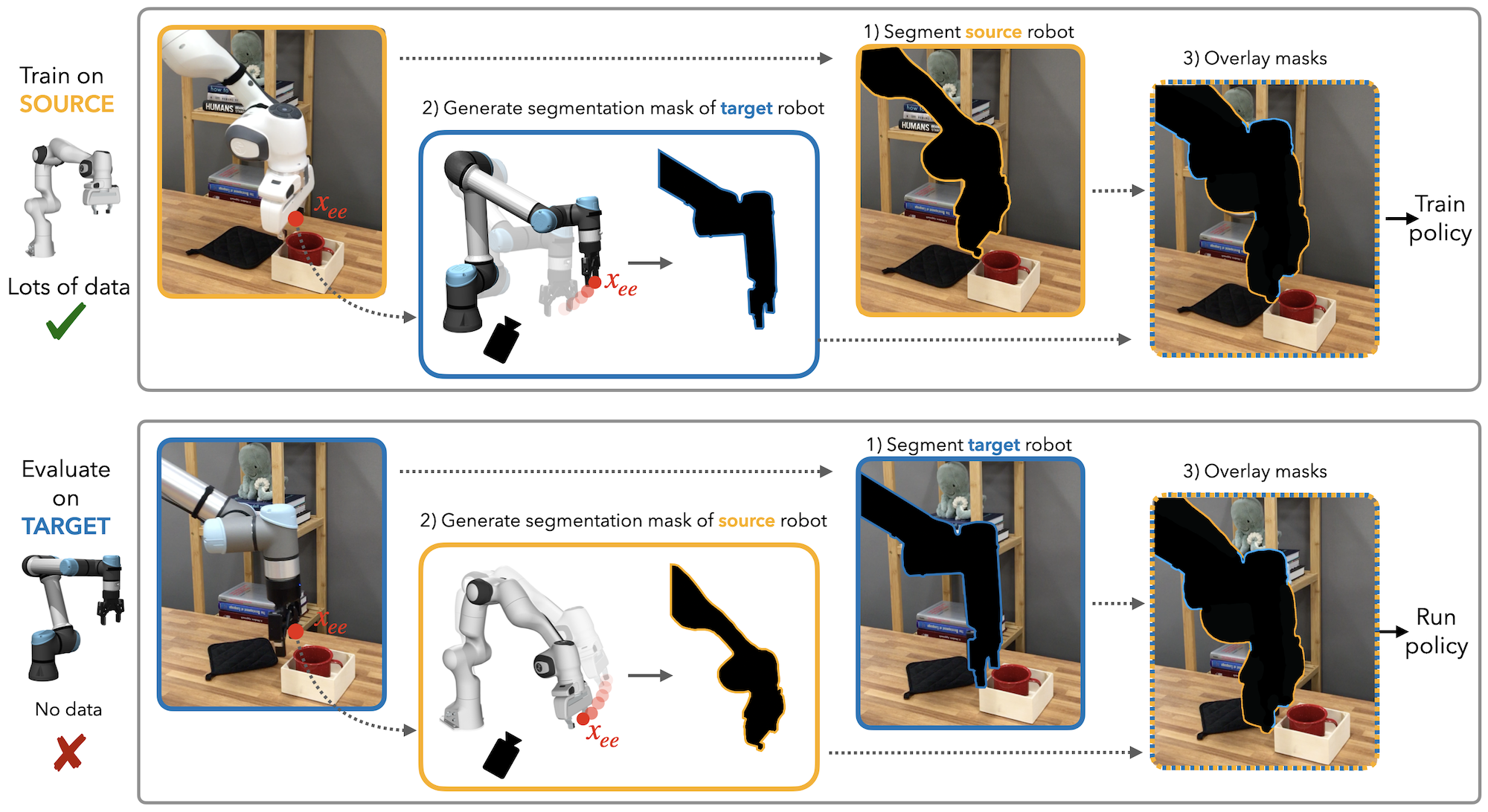
Different Robot
These are evaluation roll-outs on the source (Panda robot + Robotiq gripper), and the target (UR5e robot + Robotiq gripper). Compared to the strongest baseline (Mirage), Shadow achieves an additive increase in success rate on the target robot of +30%, +40%, +61%, and +38% over the Mug, Blocks, Cups, and Hexagon tasks, respectively. Videos at 1x speed unless otherwise specified.